Networking Archives: Quantitative History and the Contingent Archive
Abstract
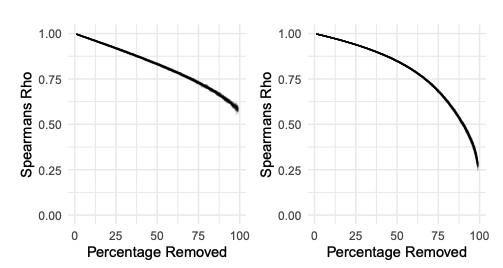
Recent years have seen a growth in the use of network analysis on large datasets of correspondence, but studies of the epistemological basis for findings have not seen a commensurate increase. The latter are important because although large, these datasets can only ever represent a fraction of the total available correspondence, and most historically contingent letter archives have significant amounts of missing or uncertain data or records. This paper outlines three approaches to the study of missing network data. first, we suggest some strategies for dealing with missing data, beginning with understanding in detail the type and extent of missing data, second, we outline a method for understanding the effect that missing data has specifically on historical letter archives, which compares rank correlations of metrics between the full network and progressively smaller random sub-samples. The experiments show that the most basic metric of network structure, degree, is remarkably robust to random letter removal even when large samples of letters have been removed. Last, the paper argues that the combinatory effect of joined-up letter networks can be used to further the understanding of the structure of seventeenth-century letter networks and intellectual exchange.
Supplementary notes can be added here, including code, math, and images.
Yann Ryan
Research Fellow, Networking Archives Project
I’ve been at Queen Mary, University of London since 2014 and recently completed a PhD in the history of early modern news.