5 Working with METS/ALTO
As mentioned in the last chapter, most of the ‘newspaper data’ produced by various projects is an output of XML files, usually with information on the location on the page of each word, and further metadata.
The most common standard used is called METS/ALTO, a standard maintained by the Library of Congress for digitising complex documents such as newspapers. Generally, an issue of a digitised newspaper will consist of two components:
A series of ALTO files, one for each page of the issue.
A single METS file for each issue
In this chapter I’ll give a brief overview of the standard, and provide some information on how it might be used. Ultimately, much of the standard digital humanities analyses will use some version of the ‘plain text’, and requires extracting that from the very complex structure of the original documents (though there are in theory ways the full METS/ALTO information might be useful, perhaps for understanding how physical layout relates to text or images, for example).
For more information on the METS/ALTO standards, take a look at the Library of Congress information pages for ALTO and for METS.
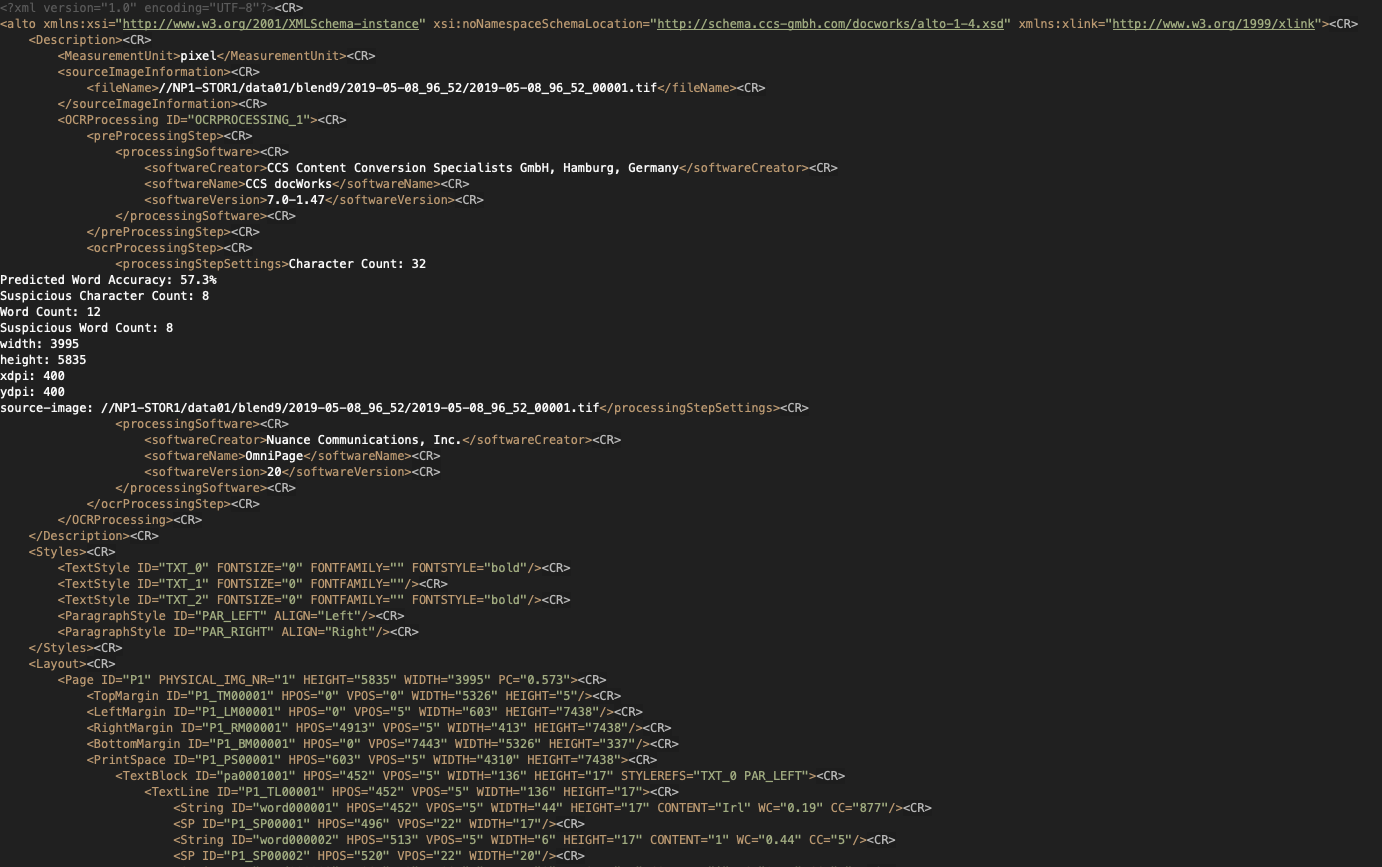
Put simply, ALTO documents record the physical coordinates of text on a page, generally divided into text blocks, text lines, and words. Each part of the text is tagged in a hierarchical tagging system, as can be seen from the screenshot below. The ALTO document also records some basic metadata about the process, such as the predicted word accuracy (which is a measure of confidence of the software, and doesn’t compare to a ‘ground truth’, so it may not be accurate), and the source image. You can see below, that the whole page is contained within a <Layout></Layout> tag, and within that are contained <TextBlock></Textblock>, within that, <Textline></Textline>, and finally <String></String> tags for each word of text.
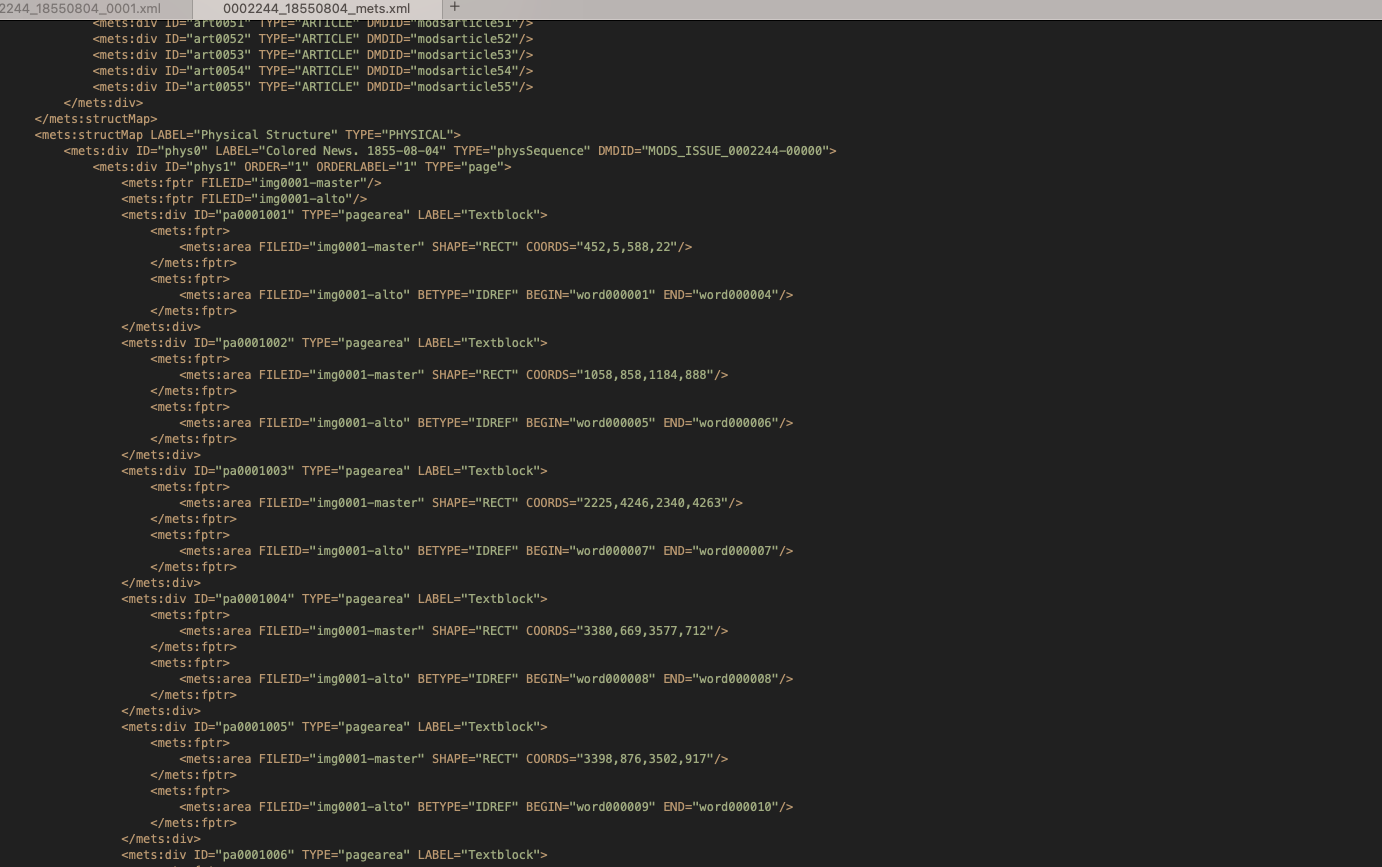
On the other hand, the METS file takes the IDs of these strings, textblocks, and textlines, and provides information on how they all fit together to make the structure of the newspaper. Generally, newspapers will be divided into different articles, and contain other items such as headers and titles. This information is recorded by the METS file. It also means that we can extract and differentiate between different articles when it comes to extracting the text.
How to work with these
The structure of these files can be daunting, and it’s true that it is not straightforward to extract the text in any meaningful way. In many cases, you’ll find that others have already created plain-text versions of newspapers, or tools to make them yourself, such as the resources created by the National Library of Luxembourg, the Impresso project, and Living with Machines. The latter, alto2text, is a command line tool which converts METS/ALTO into plain text.
The full documentation for alto2text is available via Github. It uses the python programming language, and expects the newspapers the folder format in which they can be downloaded from the Shared Research Repository.
Using R
In Chapter 9, you’ll find a series of steps in order to extract text from METS/ALTO. It’s much slower and a little clunkier than the method above, but it may be an alternative if you want to do everything within a single coding language.