A Short Guide to Historical Newspaper Data, Using R
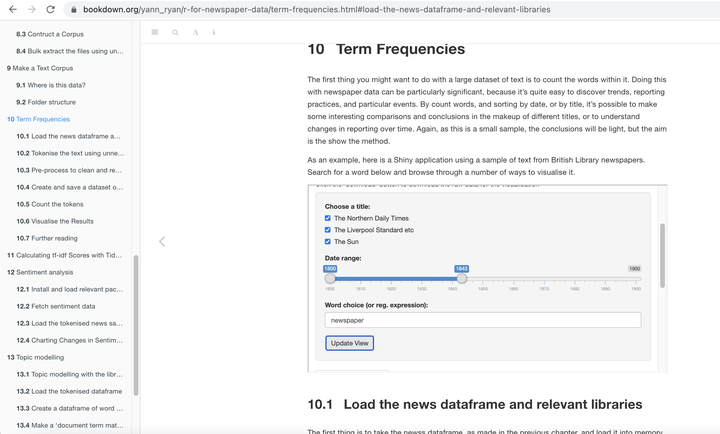 Screenshot of Application
Screenshot of Application
In 2018 and 2019 I worked at the British Library as a Curator of Newspaper Data. It was an experimental position, conceived on the premise that the data generated by newspaper digitisation projects, in this case the Heritage Made Digital project, deserves its own curatorial role and set of practices.
It was an fun time to work on such a project. While the large-scale analysis of newspaper data by historians is no longer in its infancy, it’s still probably in an adolescence, and it was exciting working within an evolving discipline, one which is developing its own set of practices, understanding where and how its bias works and the implications this might have, and generally moving from a sense of naive optimism to a practice which is more academically and mathematically rigorous and self-reflective.
This book aims to give basic handbook for those who would like to dip their toes into big data analysis but don’t know where to begin. It takes advantage of the fact that for the first time, newspaper data from British Library is available to download, in bulk and for free. It uses some of that data, walking through the process from its download to running basic DH analyses: word frequencies, sentiment analysis, topic modelling and text reuse detection. It also introduces some mapping techniques, again using a dataset produced and made available by the British Library: a metadata list of the newspaper collection, which we hope will be of use to a wide variety of researchers.
Yann Ryan
Research Fellow, Networking Archives Project
I’ve been at Queen Mary, University of London since 2014 and recently completed a PhD in the history of early modern news.